本文转自PaperWeekly微信公众号
通过搜索引擎我们可以轻松获取到海量的知识,可我们通常不会觉得一台电脑“知识渊博”——计算机并不理解这些知识,只能给你一系列相匹配的检索结果。在我们眼中,计算机更像是一座高级的图书馆,而不是一位能理解你所想所问的博学之士。
好消息是这一点正在逐渐改善。机器阅读理解,一项致力于教会机器阅读人类的语言并理解其内涵的研究,作为目前自然语言处理领域中的热门方向受到了广泛关注。与传统的问答系统不同的是,阅读理解任务更注重于对于篇章文本的理解,机器必须自己从篇章中学习到相关信息,而不是利用预设好的世界知识、常识来回答问题,所以更具有挑战性。目前 Google DeepMind、Facebook AI Lab、IBM Watson、微软、斯坦福大学(Stanford)、卡内基梅隆大学(CMU)等知名研究机构都都纷纷投入到相关研究当中。
训练机器去阅读理解人类语言的方法,和训练人类阅读外语的方法有很多相似之处,其中一个重要的手段就是填空型阅读理解。机器会看到一段文本片段,并需要回答若干问题,问题的答案就出现在这段文本当中。例如:
 ▲ 填空型阅读理解示例
▲ 填空型阅读理解示例
我们在做这样的阅读题的时候常常会发现,一口气读完文章然后仅凭着对文章的印象答题可不是一个好做法,通常需要在看了问题之后再回到文章特定的地方找答案。对机器来说也是这样,目前的大多数模型都有一个注意力机制,在看了不同的问题之后,模型会把注意力放在篇章的不同部分,从而得到更精准的答案。
来自哈工大讯飞联合实验室(HFL)的崔一鸣、陈致鹏、魏思、王士进、刘挺老师和胡国平把问题想得更深了一步。他们发现此前的研究都只把问题看作一个整体,或者只考虑了问题对篇章的影响,没有仔细考虑篇章对问题的影响,而模型实际上可以利用更多的篇章-问题之间的交互信息。他们设计了新的层叠式注意力(Attention-over-Attention),对问题进行了更细致的拆解,而不是简单将其看做成一个整体,把阅读理解的研究提高到了一个全新的水平。他们的论文 Attention-over-Attention Neural Networks for Reading Comprehension 发表在了 2017 年的计算语言学会(ACL2017)上。
论文的作者崔一鸣高兴地向我们介绍,“相比于前人工作,本文提出的模型结构相对简单且不需要设置额外的手工超参数,并且模型中的某些结构具有一定的通用性,可应用在其他相关的任务当中。实验结果表明,在公开数据集 CNN、CBT-NE/CN 数据集上,我们的模型显著优于其他基线模型,并且达到了 state-of-the-art(当前最先进)的效果。”
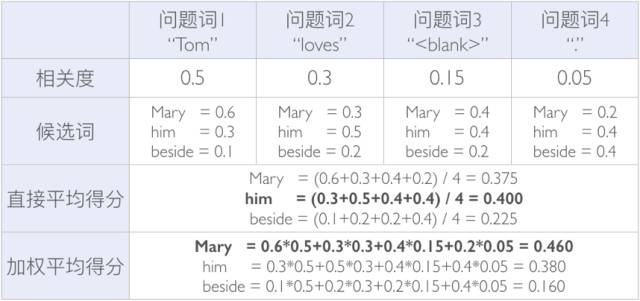
那么这个“层叠式注意力”究竟是怎么回事呢?崔一鸣举了一个简单的例子。假设我们遇到了一个填空题,“Tom loves ___.”,模型会做以下几步:
-
将篇章及问题通过词向量映射以及循环神经网络(RNN)的建模,得到包含上下文信息的文本表示;
-
对篇章和问题中的每个词两两计算“匹配度”;
-
根据匹配度计算出每个问题词的相关程度,即对于这篇文章来说,问题中的关键词是什么(表中第一行);
-
对问题中的每个词计算篇章中可能的候选(表中第二行,这里节选了三个候选词:Mary、him、beside)
鉴于不同问题词的贡献不同,求得他们的加权得分再合并,得到每个候选词的最终得分,从而找出适合填入空缺中的词(表中第四行)。
 ▲ 两种注意力计算方式的对比
▲ 两种注意力计算方式的对比
崔一鸣进一步解释道,“如果我们将问题看做一个整体,只计算一次 attention 的话,答错的几率就会大一些,通过将问题拆解,并赋予不同权重则会将风险分摊到每个词上,从整体上降低答错的概率。”在上面的例子中,如果不考虑每个问题词的相关度,直接对候选词的得分求平均,就会得出“Tom loves him.”这样的错误答案。选择“him”虽然同样符合语法,但结合篇章可以看出填入 Mary 更合理。
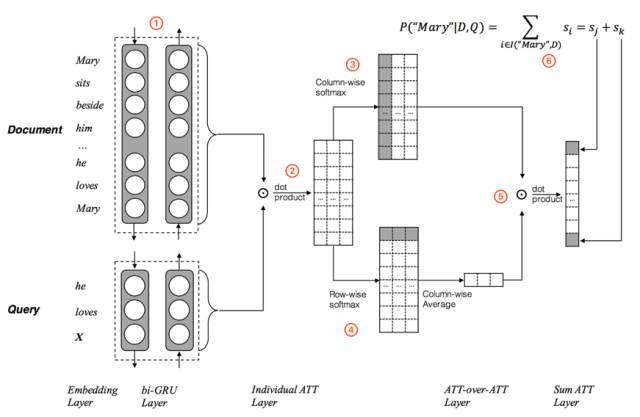 ▲ Attention-over-Attention Neural Network的模型结构图
▲ Attention-over-Attention Neural Network的模型结构图
谈到后续工作和阅读理解未来的发展,崔一鸣也与我们分享了一些看法:
“尽管近一两年来机器阅读理解的研究突飞猛进,相关神经网络模型层出不穷,但对于机器阅读理解的终极目标来说,现在还只是万里长征的开始。根据我们对目前的阅读理解数据集的详细分析,在这些公开数据集中的大多数问题都属于单句推理的问题,即回答问题只需找到文中的一个关键句即可。如何能够从错综复杂的线索以及前因后果中找到问题的答案,这对于目前的阅读理解技术来说还是相对困难的。相比于机器,人类的一大优势是能够通过多个线索来推理得到问题的答案,这是目前机器阅读理解非常薄弱的地方。如果我们真的希望机器能够‘能听会说,能理解会思考’,那么对文本的更深层次的归纳、总结、推理是未来机器阅读理解不可缺少的一部分,也是今后这项研究必须攻克的难关。不过我们相信随着阅读理解研究的逐步推进,这个问题会逐步得到改进。”
原文地址:Wechat
Nothing special