2017年10月14日,由中国中文信息学会计算语言学专委会(CIPS-CL)主办,哈工大讯飞联合实验室(HFL)承办,科大讯飞冠名的第一届“讯飞杯”中文机器阅读理解评测大会(CCL-CMRC2017)在南京完美落下帷幕。
本届评测大会与国内自然语言处理领域最具权威的全国计算语言学学术会议(CCL 2017)共同召开,也是CCL大会首次举办的评测活动。
全国计算语言学会议CCL作为国内最大的自然语言处理专家学者的社团组织——中国中文信息学会的旗舰会议,经过20余年的发展历程,已形成了十分广泛的学术影响,成为国内自然语言处理领域权威性最高、口碑最好、规模最大的学术会议。CCL着重于中国境内各类语言的计算处理,为研讨和传播计算语言学最新的学术和技术成果提供了高水平的深入交流平台。
 ▲ 哈工大讯飞联合实验室主任、哈尔滨工业大学教授刘挺发表演讲
▲ 哈工大讯飞联合实验室主任、哈尔滨工业大学教授刘挺发表演讲
从今年开始,CCL会议同期将举行评测活动。本届评测将聚焦任务设定为机器阅读理解(Machine Reading Comprehension)。让机器能听会说,能理解会思考是人工智能的长远目标,机器阅读理解作为目前自然语言处理领域中的热门研究内容受到了广泛关注。与传统的问答系统不同,机器阅读理解任务更注重于对于篇章的理解,而不是利用世界知识、常识来回答问题,所以更具有挑战性;同时机器阅读理解也受到了各大研究机构的高度重视,并且纷纷投入到相关研究当中,如Google DeepMind, Facebook AI Lab, IBM Watson, 斯坦福大学(Stanford), 卡内基梅隆大学(CMU)等。
 ▲ 科大讯飞AI研究院高级研究员、研究主管崔一鸣发言
▲ 科大讯飞AI研究院高级研究员、研究主管崔一鸣发言
本届阅读理解评测以填空型阅读理解问题为主,是阅读理解任务中的较为基础的问题。目前竞争较为激烈的Facebook CBT数据集上,人的平均答题准确率是81.6%。机器目前基于神经网络的方法已普遍可以达到准确率75%以上的效果,两者差距已非常小。另外,除填空型问题外,本届评测还同时设立了用户提问型问题的方向。与填空型任务不同的是,用户提问类任务中的问题更加真实、难度更大,且参赛者需要考虑填空型问题到用户提问型问题的迁移,使本次评测更加多元化。
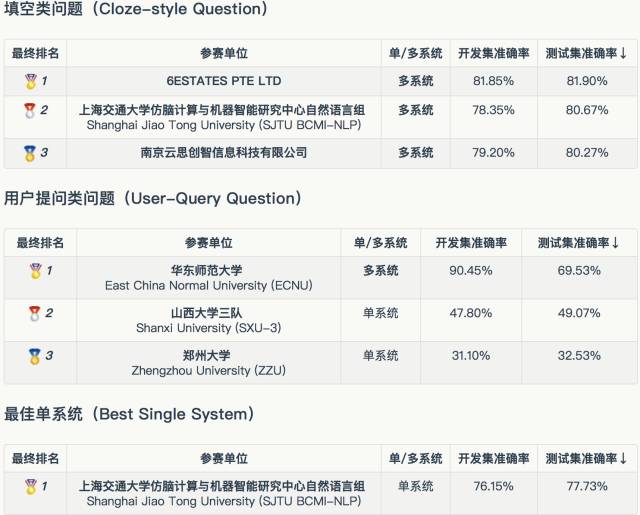 ▲ CMRC2017中文阅读理解评测最终排名
▲ CMRC2017中文阅读理解评测最终排名
本次评测大会从2017年4月份公布消息以来,收到30多家参赛单位的报名,最终有15家单位提交了评测结果。填空类任务的第一名由新加坡公司6ESTATES PTE LTD摘得,上海交大、云思创智紧随其后;用户提问类任务第一名由华东师范大学获得,山西大学,郑州大学分别位居第二、第三名。
在评测大会当天,评测会务组邀请获奖单位带来了精彩的报告,并且与参会者充分交流了比赛心得,为相关领域学者提供了良好的沟通平台,进一步推动了国内机器阅读理解的研究。同时,本届评测大会还将评测中使用的所有训练、开发、测试集公开,方便相关领域学者进行进一步的研究和探索。
Nothing special